
近期,山西大学智能信息处理研究所团队在人工智能领域表示学习研究中取得了重要进展。
机器学习旨在从经验数据中学习规律,是人工智能领域重要的研究方向。众所周知,机器学习方法的泛化性能严重依赖于数据的表示。如何获得好的数据表示是机器学习领域一直关注的问题,相关研究被称为表示学习。然而,现有的表示学习方法大多根据经验或领域知识设计,通用性不足。同时,在设计方法时缺乏对泛化误差的考虑。
针对上述问题,研究团队提出了一种基于泛化误差的准则用于度量表示学习函数的质量。具体地,将一般性的学习过程分解为表示学习过程和分类学习过程的复合。基于分解结果,学习方法的泛化误差被形式化为表示学习函数的函数。基于VC维理论,推导出泛化误差上界的一种具体形式,即得到一种准则。为了使该准则可计算,将其建模为两个优化问题的比值,见公式(1),并证明了该比值可以有效地逼近原始准则。同时,证明了得到的两个优化问题均为凸优化问题,因此可以保证获得全局最优解,从而准确地计算对应的准则。
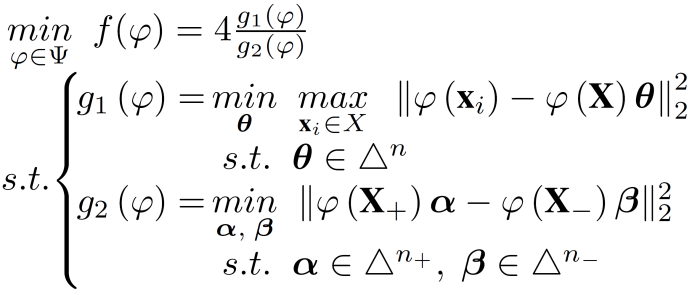 (1)
(1)
针对公式(1)中优化问题的特性,设计了基于神经网络的优化求解算法。该算法是一种特殊的内点法,因此收敛性和收敛率都有良好的理论保证。同时,该算法可以利用高性能计算硬件GPU进行加速,保证了求解的高效性。在人造数据集上的实验结果表明提出的准则可以有效地刻画泛化误差、提出的优化求解算法可以快速收敛。
我们将提出的准则用于机器学习领域两类最常用的、可以实现非线性变换的表示学习方法(核方法和深度神经网络方法)中,用于缓解两类方法各自面临的挑战。
核方法是机器学习领域一类经典的方法,核函数直接决定了此类方法的性能。我们利用提出的准则设计了一个通用的核函数选择方法。在大量基准数据集上的实验结果表明,所提方法可以从候选核函数集合中准确地选出泛化性能最好的核函数。与目前普遍采用的交叉验证方法相比,所提方法的运行结果没有随机性且运行时间更短。核函数的选择是机器学习领域长期以来公认的重要问题之一,所提方法在该问题上取得了重要的进展。
深度神经网络是目前最流行的机器学习方法,其泛化性能严重依赖于充足的标记数据。为了缓解该问题,我们利用提出的准则设计了一个通用的深度神经网络提升框架,见图1。
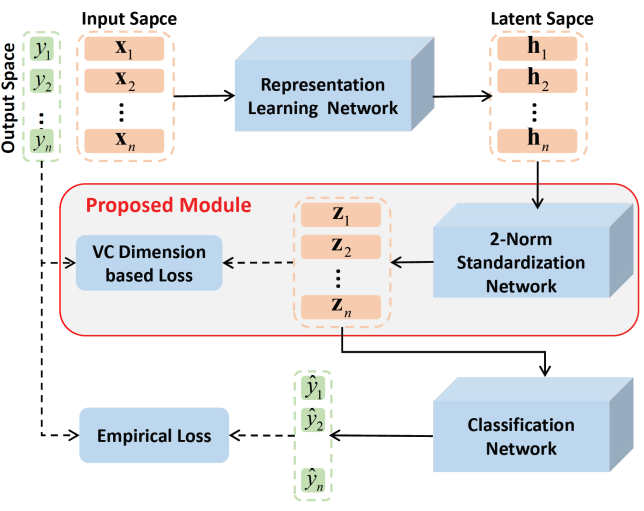
图 1深度神经网络提升框架
在公开数据集上的实验结果表明当用于训练的标记数据较少时,所提框架可以显著地提升多种深度神经网络(包括MLP、CNN、ResNet和ViT)的泛化能。深度学习方法对大规模标记数据的依赖极大地限制了其在诸多场景中的应用。提出的提升框架具有理论保证且通用性强,对于拓展深度学习方法的应用范围具有重要意义。
相关成果《A General Representation Learning Framework with Generalization Performance Guarantees》被International Conference on Machine Learning(ICML, 2023)录用。该论文通讯作者为梁吉业教授,第一作者为2018级博士生崔军彪,合作者为梁建青副教授、2020级博士生岳琴。研究工作得到计算智能与中文信息处理教育部重点实验室、科技创新2030-“新一代人工智能”重大项目、国家自然科学基金重点项目、山西省1331工程重点学科建设计划的支持。
ICML是全球最负盛名的人工智能会议之一,同时也被中国计算机学会(CCF)推荐为人工智能领域的A类会议,主要发表机器学习领域的前沿研究成果。本届ICML将于2023年7月23日至29日在美国夏威夷举办。