
近期,山西大学人工智能研究团队在自学习谱聚类的理论与方法研究中取得重要进展,相关成果以“Spectral Clustering with Robust Self-Learning Constraints”为题于2023年4月19日在人工智能领域国际顶级期刊《Artificial Intelligence》在线发表。该论文通讯作者为梁吉业教授,第一作者为白亮教授,合作者为2021级博士生祁敏学。
谱聚类是一种极具代表性的无监督机器学习范式,其相关技术已在计算机视觉、社交网络、精准医疗等领域取得了巨大的成功。然而,现有谱聚类模型更多强调学习无标记数据之间的一致性去探索数据的潜在类结构,忽略了它们的判别性对训练无监督模型的重要性。通过大量实验发现少量带有判别性的先验信息的介入可以极大地提升模型在分类任务上的表现。然而,从无标记数据中获取这些先验信息是极其困难的。此外,先验信息的准确性对模型影响巨大,错误的先验信息往往会严重影响模型的性能。如何从无标记数据中自学习高质量的判别信息去提升模型的有效性是一项具有挑战性的任务。
针对这一挑战,研究团队提出了高鲁棒的自学习谱聚类模型(见图1)。该模型借鉴集成学习的思想,从无标注数据中自学习多组监督信息,通过求解它们之间的最大一致性去增强谱聚类模型的判别性。相比现有方法,新模型能够学到更加鲁棒的监督信息和聚类结果,并通过大量实验对比验证了它的有效性(见图2)。
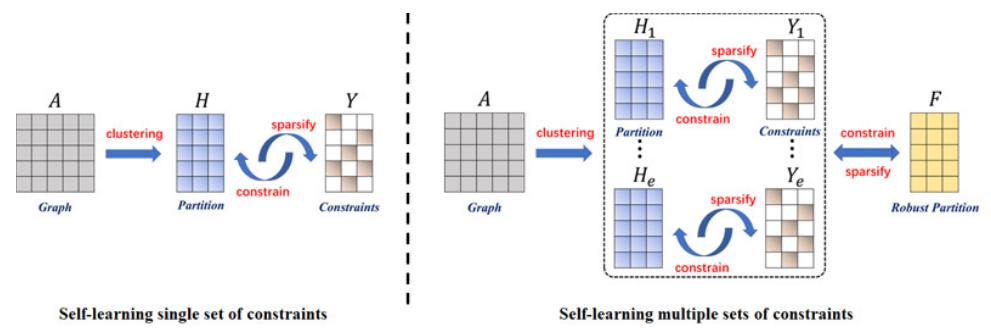
图1 高鲁棒的自学习谱聚类模型框架
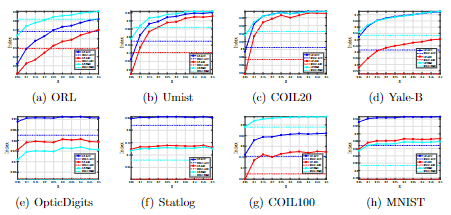
图2模型和现有方法的有效性比较
同时,团队提供了该模型的相关理论分析:(1)从泛化性的角度出发,证明了自学习的判别信息能够提升谱聚类模型的泛化能力。(2) 从稳定性角度出发,证明了自学习多组监督信息相比单组监督信息能够帮助谱聚类模型得到更加鲁棒的聚类结果。(3)从收敛性的角度出发,证明了该模型能够在有限次迭代中收敛。
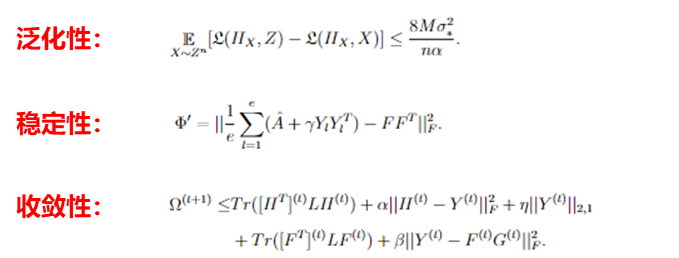
图3 模型的理论分析
研究工作得到了科技创新2030-“新一代人工智能”重大项目、国家优秀青年科学基金、山西省1331工程重点学科建设计划的支持。
据悉,AIJ期刊于1970年建刊(期刊封面见图4),是国际上公认的人工智能领域顶级期刊,同时也被中国计算机学会(CCF)推荐为人工智能领域的A类期刊,主要刊登人工智能领域的高质量前沿研究成果,每年只发表80篇左右的论文。
研究成果原文阅读链接:https://doi.org/10.1016/j.artint.2023.103924

图4 AI期刊封面